| 9.1 | Theory & History |
| 9.2 | Policy Routing Usage |
| 9.3 | Summary |
You appreciate the detailed control of the routing structure that you possess under IPv4 with Policy Routing. You ponder the scope and uses of the various parts of Policy Routing itself within the definition of your current IPv4 network. But you know that IPv4 is in transition to a more powerful and comprehensive protocol, IPv6.
With your knowledge of the workings and the reasoning behind Policy Routing under IPv4 you wonder how and what IPv6 will change in Policy Routing. To this end, this chapter explores IPv6 and especially the relationships of IPv6 to the core Policy Routing structures. At the end of the Chapter you will see where Policy Routing fits into this new protocol suite and what the future will hold.
9.1 Theory and History
By the late 1980s, members of the IETF (Internet Engineering Task Force) started discussing the possible future limitations and conceptual problems of IPv4. With the invention of the World Wide Web protocol by Tim Berners-Lee in the early 1990s came an explosion of interest in the Internet outside the academic and research oriented non-commercial Internet user base. Much of that explosion hastened the discussions of the successor to IPv4. The end result was the creation of the IPv6 protocol family whose RFCs began rolling out in 1995.
Note that there was an IPv5 specification produced in the late 1980s. However, even within the RFCs defining IPv5 it was referred to and considered as an "experimental" protocol. It was never really intended for general public consumption. Much like the Linux development kernel series, you were free to play with it but it was not expected to work or be compatible. Some of the ideas from that protocol family ended up driving some of the designs of IPv6.
IPv6 drew upon many of the ideas and lessons learned from many protocol families, not just IPv4. The auto-addressing facilities of IPX, hierarchical routing structures from OSI and SNA, and the speed of fixed packet header structures in link-layer switching, are but a few of the collective condensations of ideas. The flurry of ideas resulted in many RFCs, draft RFCs, and informational documents in 1994 as the IETF began the process of codifying the steps towards IPng (Internet Protocol Next Generation). IPng was to become IPv6 when ratified. Many of the ideas flying around in these documents were initially coalesced into the first set of IPv6 RFCs released in 1995.
RFC1883 first specified IPv6 as a standard in December of 1995. The range of RFCs from 1883 through 1888 were the first release of the new IPv6 protocol family as proposed standards. These initial RFCs have been superseded by newer developments, but most of the newer developments are merely refinements of the structures. To understand IPv6 you should obtain and read through the current standard RFC2460. To date there are several dozen RFCs that are standards or draft standards for many aspects of IPv6. A good reference site is at http://www.ipv6.org.
Many popular notions of IPv6 abound, especially in the various trade groups and magazines. For your purposes the core reasons are that IPv6 contains 128-bit autoconfiguring addresses, an aggregatable address space, and automatic routing configuration capabilities. The streamlined header and packet design refinements fix nagging issues with IPv4 such as network autoconfiguration, mobile IP, IP security, fragmentation, and source routing, and allow for very large packets known as jumbograms.
9.1.1 IPv6 Addresses
IPv6 addresses are 128 bits long. While this fact has been used to try and scare small children by various groups who had problems implementing IPv4, IPv6 addresses are actually very easy to use. You must remember that IPv4 addresses are not defined by dotted decimals. Dotted decimal notation (192.168.1.1) is merely an easy way to humanly state an IPv4 address. IPv4 addresses, as with IPv6 addresses, are more properly considered as large binary numbers. When dealing with IPv4 addresses in many cases, as you saw to some degree when you used the u32 classifier in Chapter 6, you specify them in hexadecimal equivalent (192.168.1.1 = 0xC0A80101). This is also the key to, and the standard definition of, IPv6 addresses.
There are three defined types of IPv6 addresses as specified in RFC2373 and quoted as follows:
| Unicast | An identifier for a single interface. A packet sent to a unicast address is delivered to the interface identified by that address. |
| Anycast | An identifier for a set of interfaces (typically belonging to different nodes). A packet sent to an anycast address is delivered to one of the interfaces identified by that address (the "nearest" one, according to the routing protocols' measure of distance). |
| Multicast | An identifier for a set of interfaces (typically belonging to different nodes). A packet sent to a multicast address is delivered to all interfaces identified by that address. |
Note that the broadcast address type extensively used in IPv4 is not defined. Although it could be considered a form of the multicast address type, there is no need for broadcast addressing within IPv6 because there is no need to reach every single IPv6 device.
The convention for writing down IPv6 addresses has a specification but the universally accepted method has become the coloned hex with zeros collapsed. The best way to define this is to run through a quick example.
A fully defined IPv6 address is written in human notation as eight 16-bit segments separated by colons (coloned hex notation) as follows:
1111:2222:3333:4444:5555:6666:7777:8888
Most actual addresses will contain contiguous sections of zeros. These zeros may be collapsed once and only once within the address by using a pair of colons. Consider the following full address:
1111:2222:0000:0000:5555:0000:0000:8888
This address may be specified in either of the following two ways:
1111:2222::5555:0:0:8888 First set of zeros are double colons
1111:2222:0:0:5555::8888 Second set of zeros are double colons
But the following representation is wrong:
1111:2222::5555::8888 This is illegal!
In normal usage you will usually see that the specification of the address places the double colons in the network portion of the address. That is, if the address previously had a CIDR mask of /64 then you would probably write the address as
1111:2222::5555:0:0:8888/64
This allows for the network portion to be noted as 1111:2222::/64 while the host portion is ::5555:0:0:8888/64.
All of this discussion of addressing also brings up the entire notion of routing scoping and aggregation. As you have just implicitly seen, an IPv6 address has the notion of netmask as defined by a CIDR specification. I would strongly recommend that you read through RFC2373 because it covers both the addressing and the aggregation references.
IPv6 does contain a mechanism for auto-addressing. Auto addresses are assigned in one primary use with another definition covering the concept of local addresses as you had used in IPv4 from RFC1918. In IPv6 this is the link-local and site-local address formats (see RFC2373 for details).
A link-local address is designed for exactly what the name implies. It is a valid address within the scope of the physical link itself. The other defined prefix, site-local, takes the place roughly of the local addressing space in IPv4 as defined in RFC1918. A link-local address is automatically formed from a defined prefix, fe80:, and the MAC address or alternate globally defined unique number of the interface. So, for example, if you had an ethernet card with MAC address 11:22:33:44:55:66, you would calculate your link-local address as
fe80::1122:33ff:fe44:5566
Note that this can be boiled down to the following set of steps.
| 1. | Place the link-local ID first with a pair of colons | fe80:: |
| 2. | Place the first three octets of your MAC address next | fe80::1122:33 |
| 3. | Add on fffe | fe80::1122:33ff:fe |
| 4. | Finish off with the last three octets of your MAC | fe80::1122:33ff:fe44:5566 |
Note that if your MAC address contains leading zeros, it is usually up to the particular IPv6 implementation as to how it handles the creation. In Linux, a 2 is added as a placeholder so that you have:
MAC = 00:11:22:33:44:55
Link-Local = fe80::211:22ff:fe33:4455
Note that when you consider most of the automatic routing structures under IPv6 the last 64 bits of the address are also automatically computed according to the preceding steps.
9.1.2 IPv6 Routing and Neighbors
One of the more interesting parts of IPv6 lies in the extension of the auto-address configuration to the routing structure. In RFC2461 much of the actual terminology and structure of IPv6 Neighbor Discovery is covered and is well worth reading through if only to better understand some of the conversations on IPv6.
Essentially, IPv6 provides a mechanism for hosts and routers to discover each other. You may think of ARP on IPv4, which is the link-local address mapping mechanism. If you then consider what integrating ARP with RIP would do then you have an inkling of what IPv6 Neighbor Discovery covers.
As you just saw in IPv6 addressing there are addresses that are automatically defined on your system using the MAC address of your NIC card. These link-local addresses function to ensure that there is no need for an ARP protocol in IPv6. But they also provide a means for all IPv6 devices on a local network to communicate without any further setup. The logical next step in convenience would be to have your system automatically find the routers on the network.
This next step is provided as part of the Neighbor Discovery mechanism. A router in IPv6 may be configured to send out periodic router advertisements. These advertisements are sent and received using a designated set of prefixes for routers and provide autoconfiguration of the local network for the designated advertised network prefixes. A router does not have to advertise to perform routing. Think of it more in the style of a services advertising network such as Netware SAP on IPX or the SLP (Service Location Protocol) on IPv4.
When an IPv6 host is enabled on a network, it first sends out a Neighbor solicitation, which is a query to determine what types of neighbors it has on that link. It will send out this type of query every time an address is added. It will follow this query up with a Router Solicitation query. If a router is configured to advertise on this network, the router will respond to the Router Solicitation with a Router Advertisement. If the host hears a Router Advertisement, it will create a route to that prefix on the interface it received the advertisement on.
The actual processes of this interchange and the results are determined by the configuration of the host. You can configure a host to not listen to router advertisements on certain interfaces. But for most networking where you have a single interface host and a router connecting the local network to the rest of the world this system works very well.
Now that you have some understanding of the basics of IPv6 addressing and have read through some of the RFCs, you decide to revisit your test network and try to setup a simple IPv6 network.
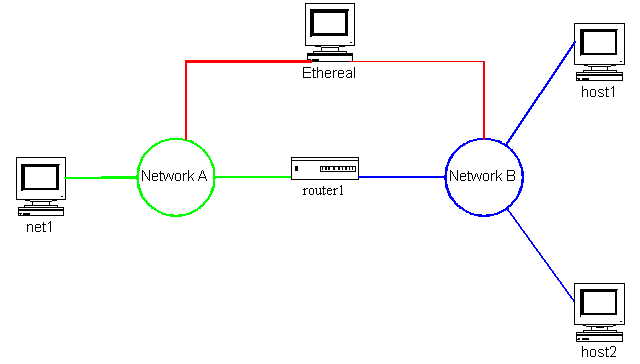
First you just want to test out the link-local autoconfiguration of the various machines on the network. Recalling your test network from Chapter 6 (see Figure 9.1.2.1) you ensure that each of the machines has a kernel with the IPv6 support compiled in. You watch the network traces while you reboot the machines. When you reboot each machine, you see that it first sends an ICMPv6 Neighbor Solicitation followed by a Router Solicitation. In all cases you then see that the systems have configured link-local addresses on their interfaces.
You then use the ping6 utility to ping from one machine to the others on the local networks. This is a real pain because you have to type out the entire address. You place the link-local addresses into the hosts file and this allows you to ping by name to make it easier.
You try to ping across router1 but, as expected, that does not work. So now you decide to try router autoconfiguration on router1 and see how it works.
9.1.3 RADVD Router Advertisement Daemon
In Linux, radvd provides the router advertisement function under IPv6. radvd only runs under the 2.2 series kernels. There is ongoing work to make sure that it will run under the 2.4 series kernels as well as an attempt to enable the router advertisement function within the IPv6 kernel code. In order to test radvd you ensure that the kernel on router1 is 2.2.12 and you obtain the radvd-0.5 source and compile it.
Once you have the daemon compiled you go about setting up a configuration file. The options for configuring radvd are numerous but there are only three options, AdvSendAdvert, AdvOnLink, AdvAutonomous, that must be present in the configuration file. After studying the man page and the sample configuration file, you come up with the following simple configuration located in /usr/local/etc/:
interface eth0
{
AdvSendAdvert on;
prefix dead:1::0/64
{
AdvOnLink on;
AdvAutonomous on;
};
};
interface eth1
{
AdvSendAdvert on;
prefix dead:2::0/64
{
AdvOnLink on;
AdvAutonomous on;
};
};
This will advertise prefix dead:1::/64 on interface eth0 and prefix dead:2::/64 on interface eth1. Now that you have this setup you start radvd while watching the traces on the networks.
As soon as you start up the daemon, you note that both interfaces send out router advertisements. These advertisements contain the prefix and the source MAC address of router1's appropriate interface.
Now you look at the routing tables on net1. You had saved the IPv6 routing tables to a file before starting the radvd daemon. This pre-radvd routing table looked like the following:
fe80::/10 dev eth0 proto kernel metric 256 mtu 1500 rtt 375ms
ff00::/8 dev eth0 proto kernel metric 256 mtu 1500 rtt 375ms
Now after you have started the radvd daemon on router1 you look at the table again and see the following:
dead:1::/64 dev eth0 proto kernel metric 256 mtu 1500 advmss 1440
fe80::/10 dev eth0 proto kernel metric 256 mtu 1500 advmss 1440
ff00::/8 dev eth0 proto kernel metric 256 mtu 1500 advmss 1440
default via fe80::2a0:ccff:fe21:eed0 dev eth0 proto kernel metric 1024 \
expires -1095sec mtu 1500 advmss 1440
You note that there is now a default route via the link-local address of router1's eth0 interface. Also, there is a route to the prefix dead:1::/64 via eth0. This is exactly what router1 was advertising. Because you know the MAC address of host2 you decide to try and ping it. You know that the prefix you told router1 to advertise on that side was dead:2::/64, so you try to ping as follows:
[root@net1/root]# ping6 dead:2:2a0:5aff:fe05:e828
PING dead:2::2a0:5aff:fe05:e828 from fe80::210:5aff:fe05:e828 : 56 data bytes
64 bytes from dead:2::2a0:5aff:fe05:e828: icmp_seq=0 hops=64 time=1.124 msec
64 bytes from dead:2::2a0:5aff:fe05:e828: icmp_seq=1 hops=64 time=430 usec
64 bytes from dead:2::2a0:5aff:fe05:e828: icmp_seq=2 hops=64 time=416 usec
64 bytes from dead:2::2a0:5aff:fe05:e828: icmp_seq=3 hops=64 time=416 usec
--- dead:2::2a0:5aff:fe05:e828 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max/mdev = 0.416/0.596/1.124/0.305 ms
Just to make sure, you try once more to ping the link-local address of host2 and you get no response. Now you know you have not even been logged in to host2 since you rebooted it with the new kernel back in Chapter 6. So the IPv6 routing is now fully functional just by having router1 advertising. Quite an impressive feat if you have only dealt with IPv4 networks in the past.
But the entire trial has also left you with an uneasy feeling. You know on the networks you have dealt with that you could always figure out the addresses of systems. If necessary, you could always ping the broadcast address for the local IPv4 network and see who answered. Under IPv6 you would ping the link-local all hosts address ff02::1 which is the rough equivalent to IPv4 broadcast. However, for individual system location your testing implies that you will need to remember the MAC addresses for all of your machines as well as know which prefix is valid for that network.
This brings up the question of defined addressing. You wonder how the routing structure would be done manually and if under such a routing structure you could assign addresses that are easier to use. To this end you decide to recode the test network using manual addressing and routing.
You first reboot router1 back into the 2.4.0.test11 kernel. You then decide to use the same prefixes as you had just used in the radvd testing. So you set up the following logical implementation:
#net1
eth0: dead:1::1/64
route added to dead:2::/64 through router1
#router1
eth0: dead:1::e0/64
eth1: dead:2::e1/64
#host1
eth0: dead:2::1/64
route added to dead:1::/64 through router1
#host2
eth0: dead:2::2/64
route added to dead:1::/64 through router1
This setup is easily implemented using the ip utility as follows for each system:
#net1
ip -6 addr add dead:1::1/64 dev eth0
ip -6 route add dead:2::/64 via dead:1::e0
#router1
ip -6 addr add dead:1::e0/64 dev eth0
ip -6 addr add dead:2::e1/64 dev eth1
#host1
ip -6 addr add dead:2::1/64 dev eth0
ip -6 route add dead:1::/64 via dead:2::e1
#host2
ip -6 addr add dead:2::2/64 dev eth0
ip -6 route add dead:1::/64 via dead:2::e1
Now you get onto net1 and try your ping6 command to host1:
[root@net1/root]# ping6 dead:2::1
PING dead:2::1(dead:2::1) from dead:1::1 : 56 data bytes
64 bytes from dead:2::1: icmp_seq=0 hops=63 time=1.627 msec
64 bytes from dead:2::1: icmp_seq=1 hops=63 time=517 usec
64 bytes from dead:2::1: icmp_seq=2 hops=63 time=507 usec
--- dead:2::1 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max/mdev = 0.507/0.883/1.627/0.526 ms
Now you are getting somewhere. This is much easier both in the command lines and in the addresses. So you now set up the hosts file on net1 to contain the addresses of both host1 and host2 using these new addresses, and you can simply issue a ping6 host2 command and get results.
The more you now consider the impact of IPv6 in your networks, the more you realize that there are several evil residues of IPv4 that will probably come back into play. Specifically the DHCP (Dynamic Host Configuration Protocol) and the DDNS (Dynamic DNS) protocols. DHCP was invented to save the hassle of running around to all the various computers on a network and coding in the IPv4 address and related information. DDNS was invented to keep current DNS mappings for all of those addresses assigned by DHCP.
You must remember that IPv6 has provided a simple and easy-to-use automatic addressing and routing structure for you if you want to just have everything plug in, turn on, and network. As with IPX, in such an environment you can assign addresses to the core servers and set them up in a DNS server and have everybody work without any need for extra configuration.
And as with IPX, you have no real control over the actual addressing that the hosts end up with although you do control the routing. This last point is most important. You do control the routing through the assignment of prefixes in the advertising routers. You can also control the actual advertising of the various prefixes to each other and to the hosts. So your extensive experience in IPX networks is a great boon to using IPv6.
On the other hand, if you want the control and need to make sure that hosts are assigned only the addresses that you would like them to have, you can. So your extensive use of DHCP in your current IPv4 networks can carry right over into the new IPv6 as well. Thus, IPv6 allows you to do whatever you want to do on the network and with the infrastructure.
This level of flexibility also allows you to have both types of configurations running side by side. You can allow most of the hosts to autoconfigure and manage the routing structure for controlling their access. And you can have select groups of hosts that obtain addresses and configuration information from DHCP. This dual personality becomes important when you start to consider the usage and interconnection of IPv6 onto the Internet.
Internet IPv6 routing does not allow for NAT and thus requires that communicating hosts have assigned legal prefixes. Under this type of configuration you can limit full Internet access on the basis of assigned prefixes and addressing. The rest of the access can be via proxy servers, thus allowing those auto-addressed hosts access to the Internet services as mediated by the routing and the proxy system.
All of this is possible because IPv6 from the beginning has allowed for, and even to some extent demanded, multiple addressing on the host. You saw some of this when you added in the static addresses and noted that the link-local addresses were still present and usable. This entire subject of multiple addressing should be old hat to you by now because it derives from the Address element of the Triad. It is also the hottest topic of discussion in the implementation mailing lists due to the source address selection mechanisms (RFCs 2460, 2461, 2462) for routing and hosts.
As one final test of your IPv6 network, you remember that Zebra (see Chapter 7) had a module for both RIPng and OSPFv3 (OSPF for IPv6). You dig the source code out on router1 and compile the ospf6d, OSPFv3 for IPv6 module. Then you give it the basic configuration used in radvd and note that the packet traces show the OSPF IPv6 packets being issued from router1. Since you do not yet have any other routers that speak OSPF6, you decide to try again when you do.
9.2 Policy Routing Usage
All of your testing with IPv6 to this point has concentrated on the basics of standard IPv6 networking. As you went through the various tests you wondered whether additional structures were available under Policy Routing. The true answer to that question at this point in time is a definite maybe.
The current IPv6 implementation within the Linux kernel, and those of other IPv6 implementations, concentrate on providing a usable networking base for core IPv6 networking functions. While the theory and practice of Policy Routing provides many instances within IPv4 networking that are easily extensible to IPv6, IPv6 still exists mostly in a beta test period.
As you read through the RFCs defining IPv6, IPSec, and the related structures of the future Internet, you will see that the fundamentals of these protocols contain many practices grown within Policy Routing. The notion of addressing as providing a multiple source for service location provides one of the concrete examples of the integration of Policy Routing structures into IPv6.
IPv6 provides a shining example of integration and growth through cross-pollination. As time passes and the entire spectra of protocols comprising the new Internet solidify through practical use you will see more of the core routing structures and extensions as evidenced by Policy Routing under IPv4 appear in ipv6. After all, you must remember that IPv4 was initiated in the early 1980s and only in the mid 1990s did Policy Routing structures begin to change the face of the Internet. The IPv6 Internet is not even a full reality yet.
Indeed at the time of this writing in late 2000, a commercial IPv6 offering is available in Japan. Parts of Europe and North America are rumored to perhaps have IPv6 commercial availability as soon as January 2001. And this does not even take into consideration the 6bone (www.6bone.org) or 6ren networks, which are available today to interested parties. There is even an IPv6 implementation of the NetFilter packet filtering available in the Linux 2.4 kernel. It even includes a fwmark facility although the RPDB cannot currently support IPv6.
This brings up the core reason why there is not an IPv6 Policy Routing structure within Linux today. Essentially, the RPDB replaced the IPv4 routing and addressing structure within the Linux kernel (see Chapter 3). The IPv6 structure within Linux was implemented outside of that core structure. Although they do share some facilities, the essential RPDB structure does not participate in or with the IPv6 addressing and routing structures. This will change, although it probably will not be until the 2.5 development kernel series slated to fork in early 2001.
Until then you have much to play with in your Policy Routing structures. The current IPv4 Internet will exist for at least another five years. And because the two network structures are coexistent, there will be use for many of the structures for some time to come.
9.3 Summary
You have seen how to implement and use a simple IPv6 routed network. There are many utilities that are IPv6 specific, such as those listed in the Linux IPv6 status pages (www.bieringer.de/linux/IPv6/status/IPv6+Linux-status.html) that you can compile and use on your IPv6 network. Both types of networking coexist so you can play with both your IPv4 and your IPv6.
From here you go on to the full scope of network routing. You have your Policy Routing knowledge and an inkling of the future to come.
Return to Table of Contents